
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- aws
- IntelliJ
- redis
- Flux
- bootstrap
- Airflow
- JavaScript
- SQL
- Python
- chart.js
- codebuild
- Jenkins
- chartjs
- Spring Error
- codepipeline
- Kafka
- kubeflow
- VPN
- AWS CI/CD 구축하기
- Spring
- docker
- 도커
- java bigdecimal
- PostgreSQL
- or some instances in your deployment group are experiencing problems.
- aws cicd
- node
- codedeploy error
- codedeploy
- COALESCE
- Today
- Total
Small Asteroid Blog
spark 설치하기 (hadoop환경) 본문
설치하고자 하는 hadoop과 spark의 버전을 확인한다.
http://spark.apache.org/downloads.html
설치파일 다운하기
wget https://www.apache.org/dyn/closer.lua/spark/spark-3.1.2/spark-3.1.2-bin-hadoop2.7.tgz
압축풀기
tar -zvf spark-3.1.2-bin-hadoop2.7.tgz
디렉토리 이름 변경하기
mv spark-3.1.2-bin-hadoop2.7.tgz/ spark
python3와 jupyter로 pyspark를 실행하기 위한 설정
cp conf/spark-env.sh.template conf/spark-env.sh
파이썬에서 pyspark 사용하기 위해 설치
pip install pyspark
환경변수 설정하기
.bash_profile 에 아래 내용을 추가하고 변경된 내용을 적용하기
[root@localhost spark]$ nano .bash_profile
[root@localhost spark]$ . ~/.bash_profilejupyter notebook 사용을 위한 설정

spark 의 실행파일들은 bin폴더에, spark 서버 관련 파일들은 sbin안에 들어있다
scala shell 을 실행시켜본다.
[root@localhost spark]$ bin/spark-shell
:q 로 스칼라 스크립트를 종료할 수 있다

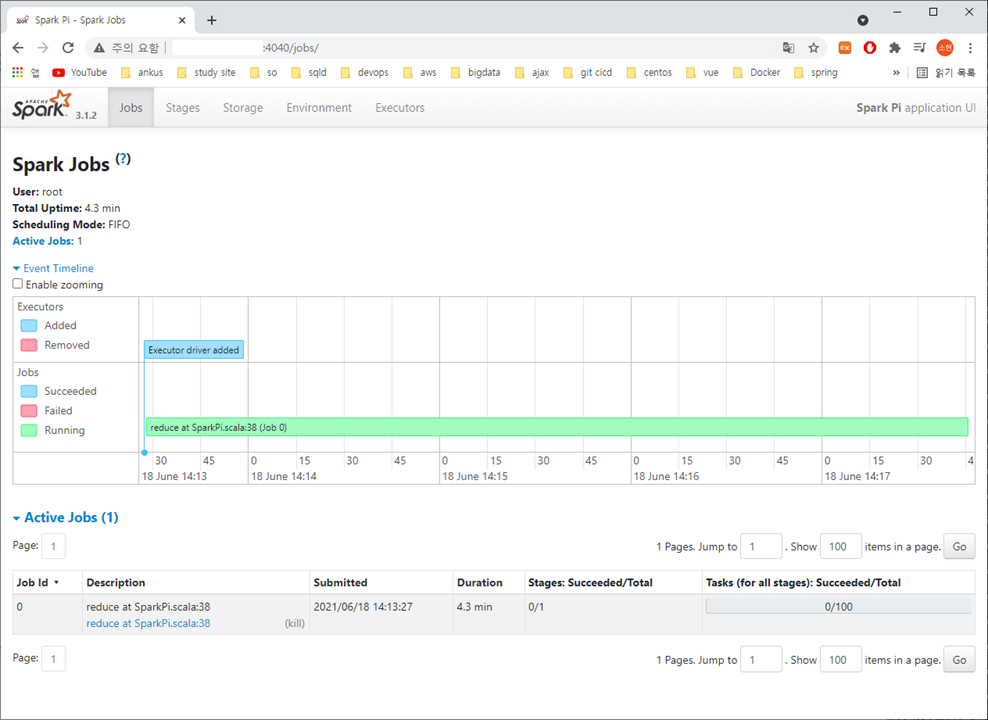
4040포트로 spark 에 접속할 수 있다.
스칼라 스크립트를 종료하면 접속은 안된다.

커널설치하기
pip install spylon-kernel
spark 제대로 작동하는데 테스트를 실행해본다.
### 테스트
spark-submit \
--master spark://ubuntu0:7077 \
--class org.apache.spark.examples.SparkPi \
~/spark/examples/jars/spark-examples*.jar \
100
나의 경우 spark 가 4040포트여서
localhost:4040 에 접속해서 확인할 수 있었다.
'데이터 & 머신러닝 > Bigdata' 카테고리의 다른 글
| [hdfs] copyfromlocal permission denied user=root access=write inode="" (0) | 2021.09.25 |
|---|---|
| 하둡 종료하기 - no datanode to stop, no nodemanager to stop (0) | 2021.06.22 |
| [spark] spylon-kernel 설치 및 확인 (0) | 2021.06.18 |
| KSB BeeAI, Azure machine learning, kubeflow 특징 (0) | 2021.03.22 |


