
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- codedeploy
- kubeflow
- codebuild
- codepipeline
- java bigdecimal
- IntelliJ
- bootstrap
- Kafka
- codedeploy error
- Python
- VPN
- AWS CI/CD 구축하기
- Flux
- chartjs
- 도커
- aws
- redis
- COALESCE
- JavaScript
- aws cicd
- chart.js
- or some instances in your deployment group are experiencing problems.
- Airflow
- PostgreSQL
- node
- Spring
- Jenkins
- Spring Error
- docker
- SQL
Archives
- Today
- Total
Small Asteroid Blog
동기 vs 비동기, 블로킹 vs 논블로킹 - 백엔드 & AI 개발에서의 활용 본문
728x90
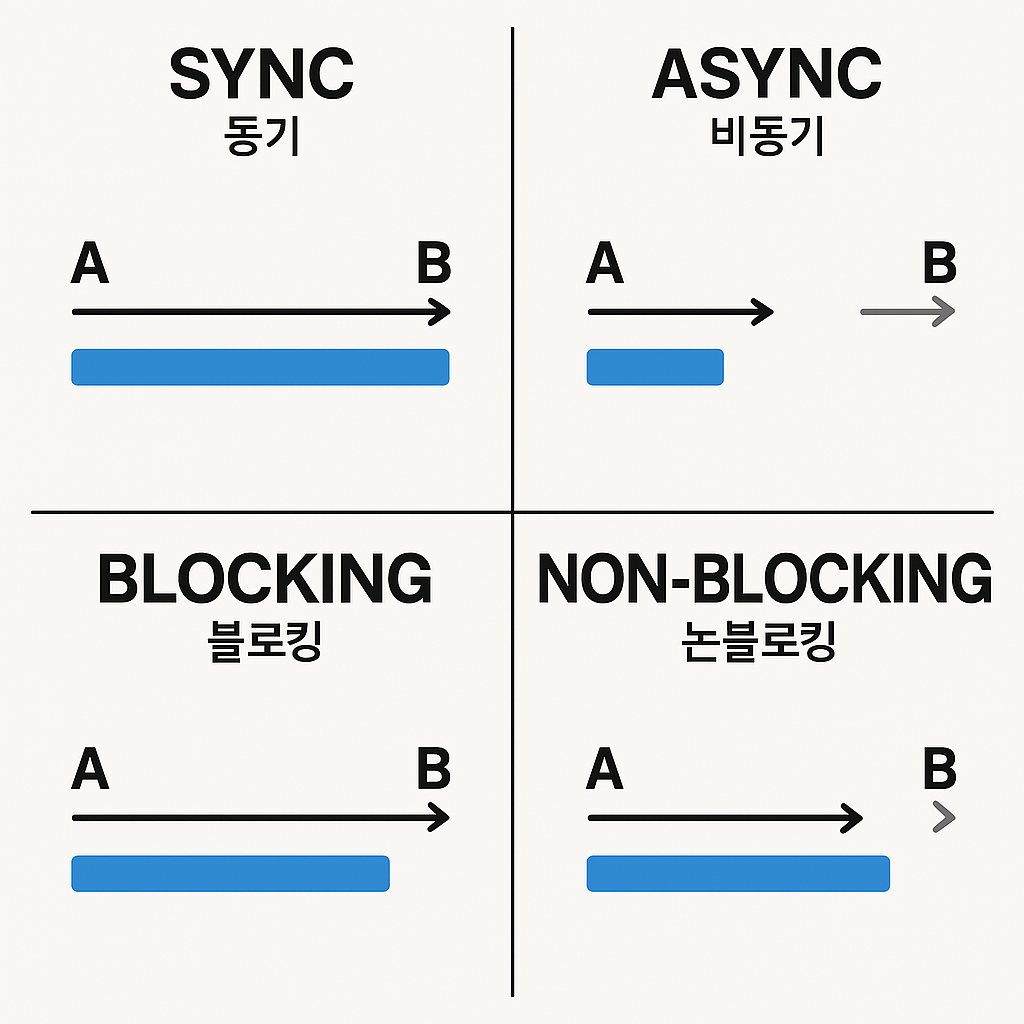
동기 vs 비동기
- 이 두 개념은 "작업의 완료 시점을 어떻게 처리할 것인가?" 에 대한 방식의 차이입니다.
- 기다릴 것인가? 기다리지 않을 것인가? 결과를 기다리는 주체는 누구인가?
✔️ 동기 (Synchronous)
- 요청 보내면 결과 올때까지 기다림.
- 호출한 함수가 끝날 때까지 다른 일을 못 함.
- 요청과 응답의 순서가 보장됨 (순차적 처리)
- 예제 : 음식 주문 후 가만히 앉아 기다린다.
✔️ 비동기 (Asynchronous)
- 요청을 보낸 후 응답을 기다리지 않고 다음 작업 실행 가능.
- 호출한 함수가 끝나지 않아도 다른 일을 할 수 있음.
- 요청과 응답의 순서가 보장되지 않음 (병렬적 처리)
- 예제 : 음식 주문 후 다른 일을 하다가 나오면 찾아간다.
블로킹 vs 논블로킹
- 이 개념은 "작업의 수행 방식과 상태 변화" 에 대한 차이입니다.
- 멈춰야 하는가? 멈추지 않고 계속 움직일 수 있는가?
✔️ 블로킹(Blocking)
- 요청한 작업이 끝날 때까지 아무것도 못 하고 기다림.
- CPU가 대기 상태가 됨.
- 앞의 작업이 완료되야 다음 작업 수행이 가능함 .
- 예제 : 음식이 나올 때까지 아무것도 안 하고 멍하니 기다린다.
✔️ 논블로킹 (Non-Blocking)
- 요청한 작업이 끝날 때까지 기다리지 않고 다른 작업을 수행.
- 앞의 작업 여부와 상관없이 바로 다음 작업 수행.
- 예제 : 음식 기다리는 동안 핸드폰을 본다.
어떻게 활용되는가?
백엔드 개발에서의 활용 예제
| 개념 | 설명 | 백엔드 개발에서의 활용 예제 |
| 동기 (Synchronous) | 요청을 보낸 후 응답을 기다린 후 다음 작업 수행 | - HTTP 요청 처리 (RestTemplate) - 데이터베이스 조회 (JDBC) - 순차적인 로직이 필요한 서비스 (ex. 결제 처리) |
| 비동기 (Asynchronous) | 요청 후 응답을 기다리지 않고 다른 작업 수행 가능 | - 이벤트 기반 서버 (Spring WebFlux, Node.js) - 대량 요청을 처리하는 웹 서버 (ex. 알림 시스템, 메시지 큐) - 데이터 처리 파이프라인 (Kafka, RabbitMQ) |
| 블로킹 (Blocking) | 작업이 끝날 때까지 현재 프로세스가 멈춤 | - 일반적인 JDBC SQL 쿼리 - Thread.sleep() 사용 - 동기 파일 I/O (FileReader, BufferedReader) |
| 논블로킹 (Non-Blocking) | 작업이 끝나지 않아도 프로세스가 다른 작업 수행 가능 | - NIO (Non-Blocking I/O)를 활용한 네트워크 서버 - CompletableFuture 비동기 API 요청 - WebFlux 기반 API |
✔ 백엔드 개발에서의 선택 기준
- 단순한 API 요청/응답 → 동기 + 블로킹
- 대량의 동시 요청 처리 → 비동기 + 논블로킹
- DB 처리, 파일 I/O → 블로킹(일반적) → 논블로킹으로 최적화 가능
- 이벤트 기반 처리(Kafka, 메시지 큐 등) → 비동기 + 논블로킹
AI 개발에서의 활용 예제
| 개념 | 설명 | AI 개발에서의 활용 예제 |
| 동기 (Synchronous) | 요청을 보낸 후 응답을 기다린 후 다음 작업 수행 | - 모델 학습 시 데이터 로드 (pandas, PyTorch DataLoader) - API 요청으로 데이터 가져오기 (requests.get()) - 모델이 한 스텝 학습을 완료한 후 다음 스텝 진행 |
| 비동기 (Asynchronous) | 요청 후 응답을 기다리지 않고 다른 작업 수행 가능 | - 데이터 파이프라인 처리 (Apache Airflow, Dask) - 모델 서빙 시 여러 요청 동시 처리 (FastAPI, gRPC) - 배치 처리 없이 실시간 데이터 스트리밍 (Kafka, Spark Streaming) |
| 블로킹 (Blocking) | 작업이 끝날 때까지 현재 프로세스가 멈춤 | - CPU 연산 (numpy, scikit-learn) - 동기적인 모델 학습 (TensorFlow, PyTorch) |
| 논블로킹 (Non-Blocking) | 작업이 끝나지 않아도 프로세스가 다른 작업 수행 가능 | - GPU 연산 (CUDA, TensorFlow async execution) - 비동기 API 호출 (aiohttp, asyncio) - 스트리밍 데이터 처리 (Kafka, TensorRT Inference Server) |
✔ AI 개발에서의 선택 기준
- 모델 학습, 데이터 로드 → 동기 + 블로킹
- 서버에서 다수의 AI 요청 처리 → 비동기 + 논블로킹
- CPU 연산 기반 머신러닝 → 블로킹
- GPU 기반 딥러닝 추론 → 논블로킹
728x90
반응형
'백엔드' 카테고리의 다른 글
| oh-my-zsh 터미널에서 사용하는 git 단축키 (0) | 2025.04.07 |
|---|---|
| Spring WebFlux와 Python의 FastAPI (1) | 2025.03.10 |
| PKCS#5 패딩과 PKCS#7 패딩의 특징과 차이점 (0) | 2024.07.18 |
| FCM(Firebase Cloud Messaging) (0) | 2024.01.12 |
| [스프레드 시트] 구글 스프레드 시트에서 다른 시트에 있는 데이터를 원하는 데이터 추출하기 (모두 찾기/전체 검색) (0) | 2023.12.04 |